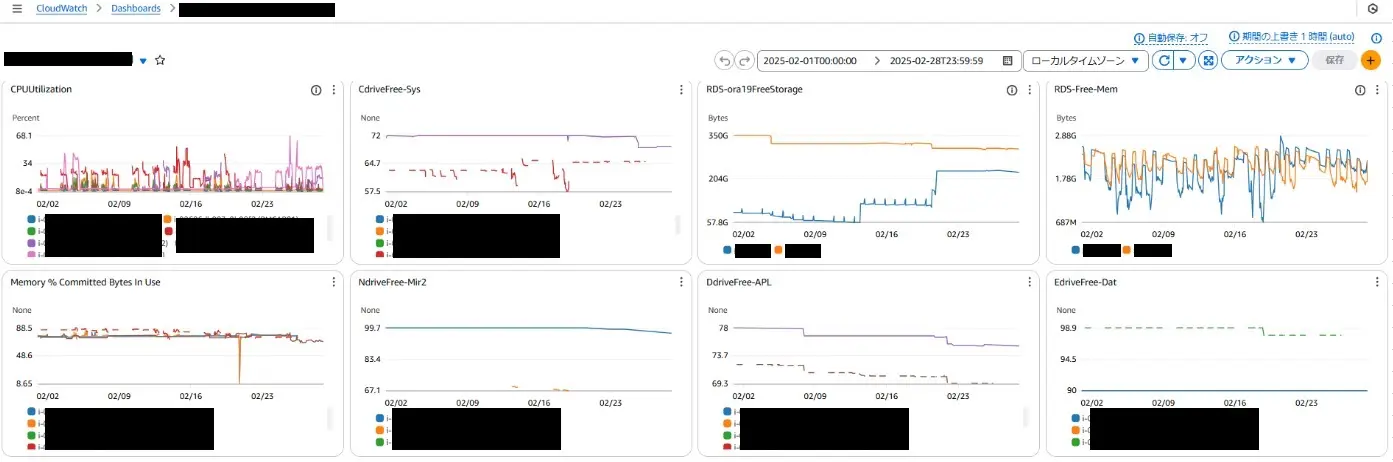
サーバが知らん間に状態おかしなってたら困る。急にディスク利用率上がってたり、固まってたり。
状態確認様にcloudwatchのダッシュボード使ってる。
ホストごとに色変えてグラフ表示してくれるし、時間帯をマウスでドラッグ選択したら拡大表示できて便利。
awsのec2ホストは、メトリクスっていうてCPU利用率見せてくれたり、状態監視のためのアラーム設定ができる。
メモリとディスクのメトリクスは このへん で設定してる。
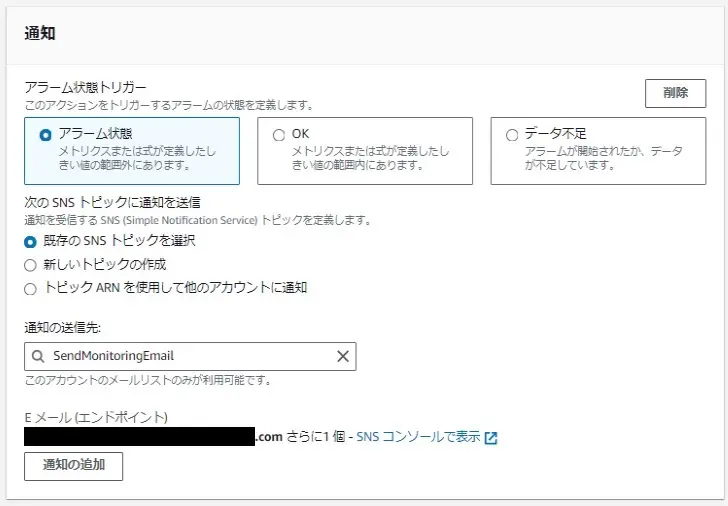
CPU、メモリ、ディスク、サーバ本体の死活監視をして、問題出たら メール飛ばす 。
アラーム設定の入り口はcloudwatchにあるで。
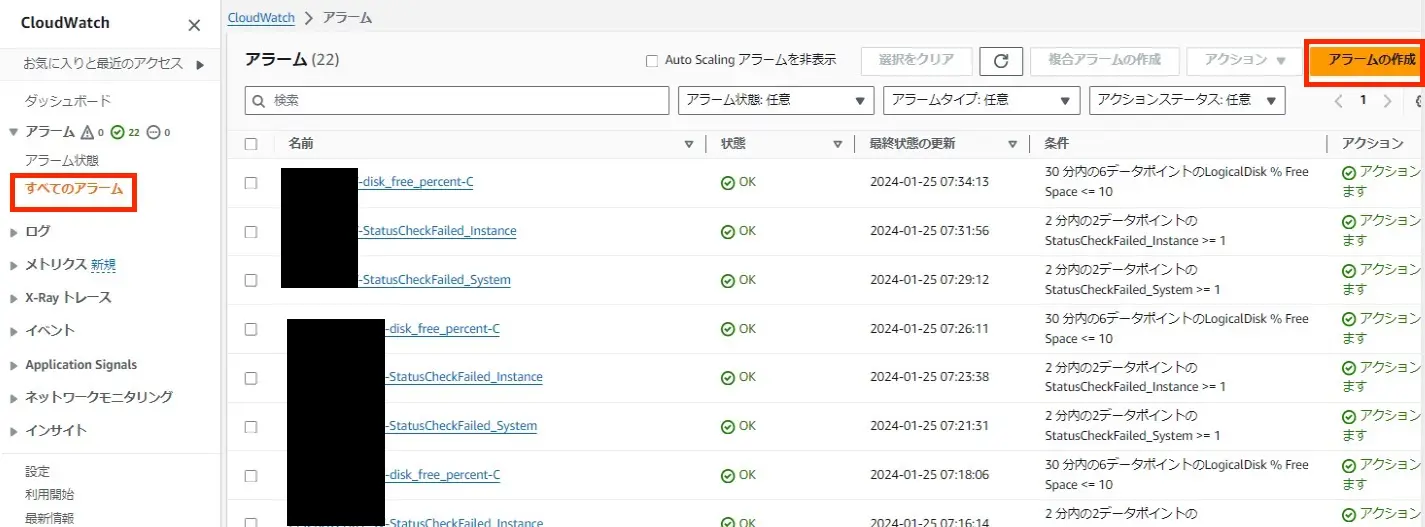
ec2停止してたりrds停止してたら、監視先からデータが取れへんから、緑色で「OK」って出てる箇所が変わる。
アラーム設定の参照
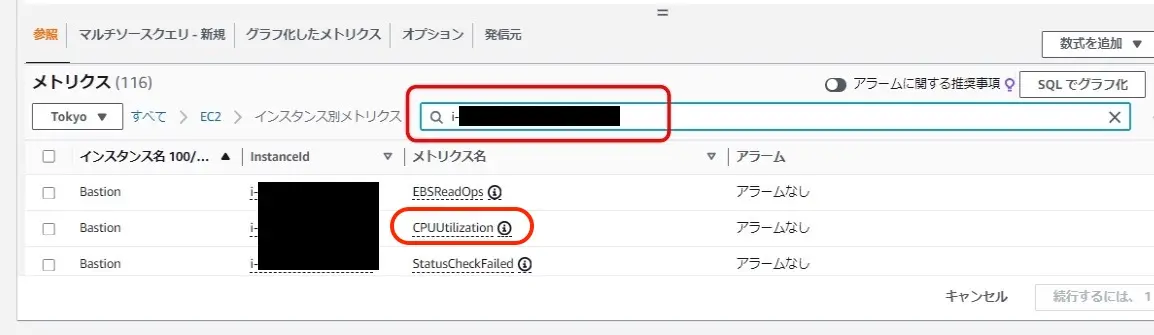
監視させるためにアラーム設定を作ってく。まずはメトリクス指定して監視設定。
項目めっちゃ多いし、全部は使ったことない。
インスタンスタイプ変えたらInstanceIDが変わってまうから、サーバ本体の死活監視以外は再設定せなアカンで。
CPUの監視
例えばインスタンスIDで絞って参照させる。CPUUtilizationでCPU利用率を使う。
閾値設定は5分間隔で「平均利用率80%オーバ」とかにする。
メモリとディスクの監視
CloudWatchAgent経由で取得してるから、カスタム名前空間から選ぶ。
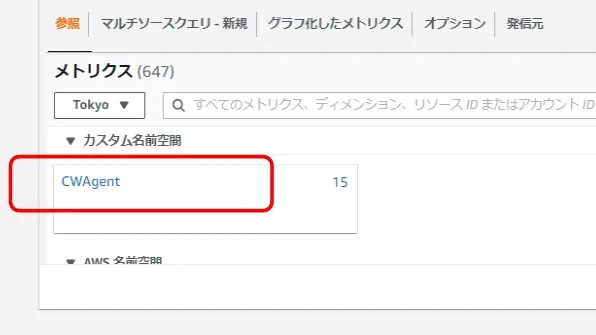
どっちがどっちやったか忘れたけど、メモリとディスクの監視のためにたどってく。
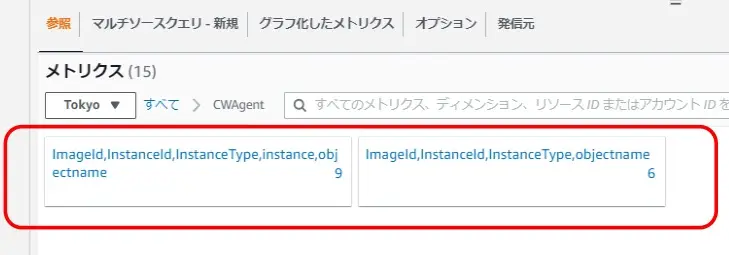
メモリ利用率のメトリクス選ぶ。

ディスク空きパーセンテージのメトリクス選ぶ。ec2-windowsホストやったらドライブ名も見える。

閾値設定は30分間隔の平均値で「80%オーバの利用率になったら」とかにしてる。
RDSの場合
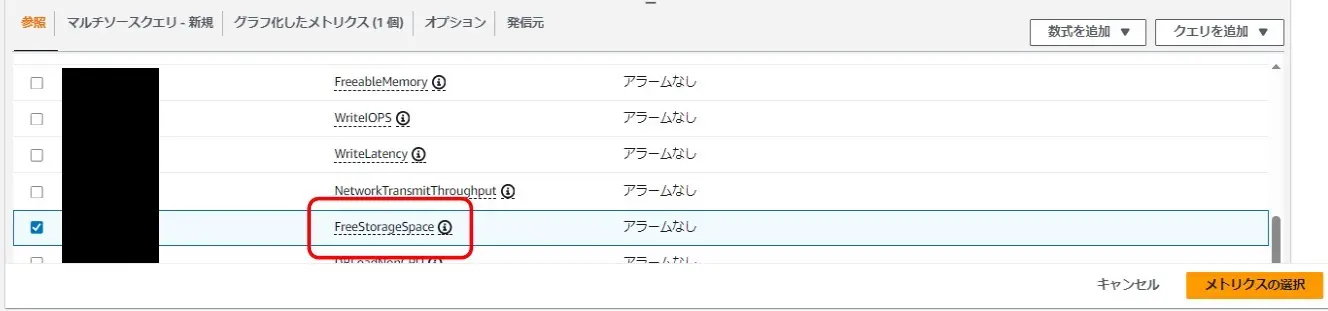
RDSの系列をたどる。インスタンスタイプ変えたら監視外れてまうはずやけど、どやったかな。

RDSで使ってるディスクの空き容量が監視できる。oracleのデータポンプでエクスポートとかされると消費されて枯渇してるって監視メール飛んでくることある。
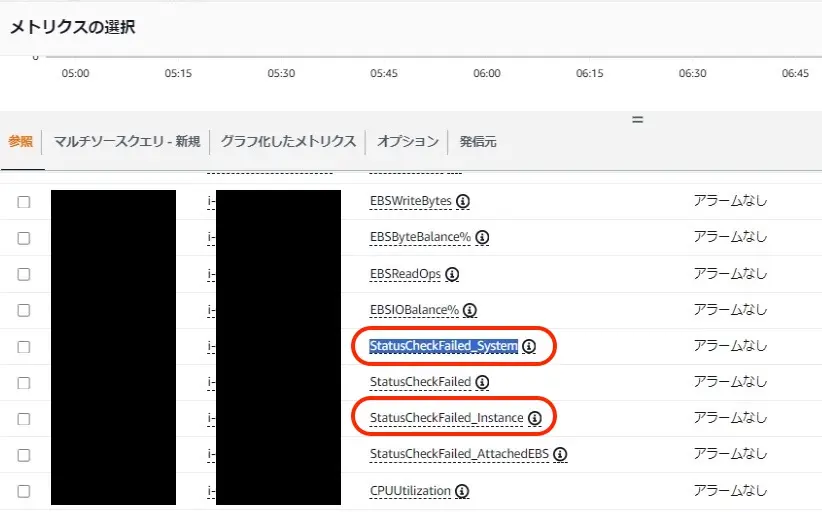
サーバ本体の死活監視
StatusCheckFailed_Systemは、
このへん
に解説あるけどVMそのものがおかしくなったことを検出できるはず。
StatusCheckFailed_Instanceも、
このへん
に解説あって、NICに向かってヘルスチェックやってる。
どっちも使う。
サーバ状態おかしくなったら1が戻ってきたっけ。
プロセス監視
やったことないけど、できるらしいってことは知ってる。
判明したら書き足す。
条件とメールの設定
監視でアラート通知する条件を設定する。閾値には整数値を書く。
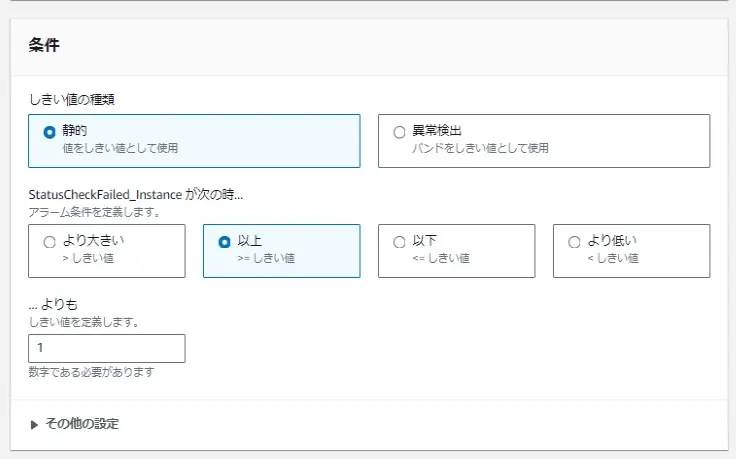
計算面倒やけど、RDSのディスクの利用率は「10GB下回ったら」みたいな設定するとき、ギガバイトをバイトに読み替えて整数値で書く。
10GB=10 x 1024 x 1024 x 1024 = 10737418240byte
構築当初は100GBでRDS動かしてたのを、データ流し込んで入らへんかもとかで200GBに増やしたりしたら、監視も連動して閾値の変更せなアカンで。
監視でアラート通知先を設定する。
アクションも設定できる
「死活監視で異常検出したときはOS再起動」みたいな設定もできる。
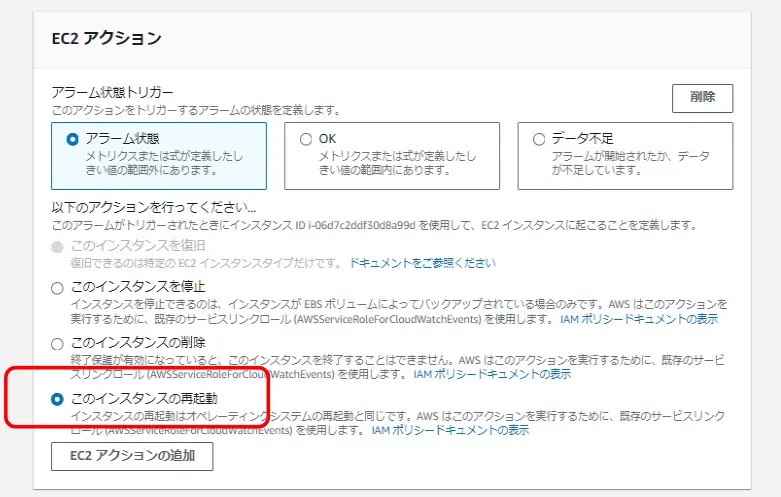
この設定はインスタンス監視で設定してる。
おかしくなった状態は一度も見たことないんやけど、ジョブ管理サーバでこれ発生したら悲惨やな。
テスト
awsではアラームのテストができる。
aws cloudwatch set-alarm-state --alarm-name [アラーム名] --state-value ALARM --state-reason "[ホスト名]"
たとえばこんな指定をawsのwebコンソールでCloudshell起動して使う。
普段はec2ホスト単位でテストしてるから、アラームテスト用のテキストを用意しといて、一括でメール飛ばす。
aws cloudwatch set-alarm-state --alarm-name GVIS-win2022-SV-disk_free_percent-D --state-value ALARM --state-reason "GVIS-win2022"
メールがこんな感じでくる。めっちゃ冗長で読みにくい。
|
|