オンラインストレージ
ってのがある。クラウドストレージともいう。
個人利用ではgoogle cloudとペアでの
google drive
しか使わん。サイズが2TBのを年1万円台で2つ。
awsには
s3
があって、バックアップ置き場やったりログ置き場に使う。
wikiに書いてある耐障害性見たら、良さそうな悪そうな・・・。データをロストすることもあるし、年に1時間ほど止まるってか。
1
2
3
4
5
6
7
|
耐久性は年99.999999999%であり、年間1TBあたり10バイトのデータが消失する。
Amazon Elastic Block Storeは耐久性は年99.8~99.9%であり、
こちらは、年間1TBあたり1~2GBのデータが消失しているが、
圧倒的にS3の方がデータ消失の量が少ない。
可用性は99.99%であり、年間平均1時間弱の停止時間がある。
こちらはAmazon Elastic Block Storeの99.999%よりも悪い。
|
クセがあるし、ファイルサーバっぽく使うこともできるんやけど、ライフサイクル管理やらバージョン維持ができるから、設定きちっとやらんと費用が異様に上がることもある。
やったことないけど、winscpでもデータ扱えるらしい。そういえばcyberduckとかrcloneにも選択肢あったよな。
普段使いならStandardでええんやけど、
ストレージクラス
ってのがあって、たまにしか使わんときは「読み書き遅いけど保管料安め」のGlacierとか選べる。
普段の設定方針#
- ec2ホストから
aws cliでコマンドライン利用させる
-
バージョン維持
やらんのと、
パブリック利用もやらん
- 特定のフォルダをバックアップ置き場にして
ライフサイクル
管理させて、保管期限が過ぎたデータは削除する
s3バケット作成#
普通に作る。

名前指定して作成。

もちろんプライベート公開ね。

保存期間設定(ライフサイクルルール)#
バケットへのライフサイクルルールを作る。

ルール名入れといて、バケット全体に有効なルールをまずは作る。

アップロード途中でなぜかエラーになったとかいうときのため、「有効期限切れ〜」のチェック入れとくと、中途半端にアップロードして残ってしもたデータを削除してくれる。

日数を1日にしとくことで、翌日には消してもらう設定にする。

作成したらルールが一覧に表示される。

特定のフォルダへのライフサイクル指定#
影響範囲をバケット全体やなくて特定のフォルダ、例えば「backup/」って指定する。
ルールスコープ指定の末尾にはスラッシュつけとかなアカン。
ブラウザのawsコンソールからデータ操作#
s3には壁があるから、それを超えるサイズで
アップロード
・ダウンロードはエラーになったはず。
1
2
3
4
|
・Amazon S3 コンソールを使用すると、アップロードできるファイルの最大サイズが160GB
・160 GB を超えるファイルをアップロードするには、AWS Command Line Interface (AWS CLI)、AWS SDK、またはAmazon S3 REST APIを使用
・AWS SDK、REST API、または AWS CLI を使用して1回のオペレーションでオブジェクトをアップロードするとき、1回のPUTで最大5GBの単一のオブジェクトをアップロード可能
・マルチパートアップロード API を使用すると、最大 5 TB のサイズの単一の大容量オブジェクトをアップロード可能
|
ちょっと保存、とかやったらブラウザ利用のGUIでええけど、コマンドラインやったら勝手に
マルチパート
で処理してくれる。
保管期間すぎたらどうなるか#
期限が到来したらファイルは削除される。
s3特有の話やと思うんやけど、フォルダの中が空になったらフォルダそのものが消える。
フォルダが消えて、また同じフォルダ名使ってデータ保管したら、ライフサイクル指定はそのフォルダに適用される。
バージョン指定は使わない#
利用料金が膨れるの怖いなぁ。
バージョニングは使わん。
フォルダのサイズをマメに確認してたらええけど、運用入って初めて気づくことあるんかも。
帯域幅の指定#
ダウンロードとアップロードのときの速度は、指定しとかんと青天井やったはず。最大は100Gbpsやったかな。
帯域幅使い尽くされて「ネットつながらん」って言われたり、バッチ処理でタイムアウトになったら困るから、回線速度の10%ぐらいを最大値に設定しといたらええんとちゃうか。
aws cliでこう指定しとく。
aws configure set default.s3.max_bandwidth 100MB/s
vpcの中だけやったら300MB/sにしといてもええかもしれんけど、オンプレやったら100MB/sぐらいがええんとちゃうかなぁ。
バッチファイルとかシェルスクリプトから使うときは、アップロード・ダウンロードの直前に書いて設定しといたらええはず。
ログ保管#
cloudtrail設定するとバケット自動作成される。このs3バケットにはさらにチェック箇所を増やしとく。

有効期限を指定しとく。例えば、1095は365日x3年の数。

日数入れたら、現行バージョンと非現行バージョンの両方にも設定入ったはず。
入ってなかったら日数入れる。
帳簿の保管期間7年とか、iso9001で指定してる文書保管年数とか、企業によってはルール持ってるやろから年数を設定したらええ。
ec2からs3バケット利用#
s3バケットは作っただけやとawsのwebコンソールからしかデータ操作できん。
主にec2から使わせるから、ポリシー作ってロールにくっつけてからec2のIAMロールに設定しとく。
ポリシーとロールを作ってec2ホストに権限つけとく#
ロールの中にある許可ポリシー設定する。GUIでも作れるけど選べる内容多すぎるからコピペして作る。

nari-s3-bucket - IAMポリシー
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
{
"Version": "2012-10-17", ⭐️日付は気にしない、こういうもんや
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow", ⭐️表示・読み書き・削除を許可する
"Action": [
"s3:ListBucket",
"s3:GetObject*",
"s3:PutObject*",
"s3:DeleteObject*"
],
"Resource": [ ⭐️対象バケットからarnで指定
"arn:aws:s3:::*nari-s3-bucket*",
"arn:aws:s3:::*nari-s3-bucket*/*"
]
}
]
}
|
作ったロールをec2ホストに権限つけとく。この設定をrdsにつけといたら、s3バケットへダンプを書いたり取り込んだりできる。

認証設定つけとくやり方#
認証設定つけるやり方もある。IAMにあるユーザ設定画面で、アクセスキーとシークレットを設定しとく必要がある。
1
2
3
4
5
|
C:\Users\administrator> aws configure
AWS Access Key ID [None]: XXXXXXXXXXXXXXXXXXXX
AWS Secret Access Key [None]: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Default region name [None]: ap-northeast-1
Default output format [None]: json
|
個人利用やったらコレでもええけど、awsコンソールの管理者ユーザの認証情報がパクられたらバケット操作だけやなくて他にも色々できてまうからセキュリティ的に致命的。
危ないから、aws管理者ユーザにアクセスキーとシークレット使うの禁じてる企業多いはず。
権限を限定したユーザで有効にするとか、ダミーデータが入ったテスト環境でだけ有効にするとかせなアカン。
コマンドライン利用#
aws cliが使えるようにec2ホストにインストールしとく。windows版だけやなくて、mac/linuxでもコマンドラインは同じように使える。
AWS CLI の最新バージョンのインストールまたは更新 - AWS Command Line Interface
インストールしたらバージョン表記させて、使えるようになってることを確認しとく。
1
2
3
|
C:\Users\administrator> aws --version
aws-cli/2.15.0 Python/3.11.5 Linux/5.15.0
C:\Users\administrator>
|
次に、バケット利用のために設定した許可ポリシーが使えるか確認してく。
バケットへのアップロード#
aws s3 cp {ファイルパス} s3://{バケット名}/{パス}
実際にはこう使う。バケットにフォルダがあらへんかったら作ってくれる。
C:\Users\administrator> aws s3 cp "C:\Users\Administrator\Desktop\s3ファイル.txt" s3://nari-s3-bucket/
C:\Users\administrator> aws s3 cp "C:\Users\Administrator\Desktop\backup\*" s3://nari-s3-bucket/backup/ --recursive
進捗が表示されるから、エコー結果をログに吐き出させたら量が多くなりがちやから、--no-progressってつけたほうがええかも。
バケット内のファイル一覧#
あんまり使わん。
aws s3 ls s3://{バケット名}/{パス}
こう使う。
C:\Users\administrator> aws s3 ls s3://nari-s3-bucket/backup/
バケットからのダウンロード#
aws s3 cp s3://{バケット名}/{パス} {ファイルパス}
デカいデータのときはディスクの空き容量に注意。
aws s3 cp s3://nari-s3-bucket/s3ファイル.txt "C:\Users\Administrator\Desktop\"
バケット内のファイル削除#
aws s3 rm s3://{バケット名}/{ファイルパス}
ファイル潰す。
aws s3 rm s3://nari-s3-bucket/s3ファイル.txt
フォルダごと潰す。
aws s3 rm s3://nari-s3-bucket/backup/ --recursive
バケット間の同期コピー#
rsyncみたいな感じ。--deleteってつけると1つめの引数のバケットになくて、2つめの引数のバケットにあるファイルとフォルダは削除される。
aws s3 sync s3://{バケット名}/{パス} s3://{バケット名}/{パス} --delete
東京リージョンで保管したバックアップを、大阪リージョンにミラーさせるとかに使う。
実務ではオプション増やした。
aws s3 sync --no-progress --copy-props metadata-directive --delete s3://nari-s3-bucket-east s3://nari-s3-bucket-west
バケット間の移動#
移動の途中でaws障害あったりして失敗したら悲惨なことになるから、元をコピーしてから削除するようにして移動は使わん。
aws s3 mv s3://{バケット名}/{パス} s3://{バケット名}/{パス}
デカいダンプがあってダウンロードするディスクの余裕がなかったら、バケット間で移動させたらええけど、これも怖いな。
aws s3 mv s3://nari-s3-bucket-east/backup/xx.dmp s3://nari-s3-bucket-west/backup/
s3バケットへバックアップするバッチ処理のサンプル#
バッチ処理使って処理させるときのサンプル。
例えばバケットのbackupってフォルダに保管期限を7日にしといて日付、ホスト単位で保管させる。
1
2
3
4
5
6
7
8
9
10
11
12
|
バケット/backup/
L yyyymmdd1
L host1
L backup
L host2
L backup
:(中略)
L yyyymmdd7
L host1
L backup
L host2
L backup
|
iniファイル#
バケット名や帯域幅設定などを別ファイルに定義しといて、バッチ処理に読み込ませて使う。
D:\gvis\variable.ini - 定数定義
1
2
3
4
5
6
7
8
9
|
; script base folder
SCHOME=D:\_GVIS\
; aws s3 name
AWS_S3_BUCKET=nari-s3-bucket
; aws s3 bandwidth
; 帯域食いつぶさないように設定。1000MB/sだと10GBのデータでも1分ぐらいで終了
AWS_S3_BANDWIDTH=1000MB/s
; ログ保管期間
LOG_KEEP=7
|
バッチ処理本体#
引数の1つめに、windowsホスト側のフォルダを指定。
引数の2つめに、バケット内の保管フォルダを指定。
syncやなくて、アップロード先を削除してから保管フォルダをバケットに作ってアップロードしたときの処理。
D:\gvis\s3backup.bat - s3バケットへのアップロード
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
@echo off
rem ## -------------------------------------------------------------------------
rem ## Name : s3backup.bat
rem ## Created by : gvis
rem ## on : 2025.7.28
rem ## Updated by :
rem ## on :
rem ## Comments : S3バケットへアップロード
rem ## Args : 1)バックアップ対象フォルダ指定(例: D:\backup)
rem ## : 2)保管先s3フォルダ指定(例: backup)
rem ## ret : 0:normal end other:abend
rem ##
rem ## -------------------------------------------------------------------------
rem ## ---set env---------------------------------------------------------------
for /f "tokens=1,* delims==" %%a in (D:\gvis\variable.ini) do (
set %%a=%%b
)
set DATESTR=%date:~0,4%%date:~5,2%%date:~8,2%
set LOGFOLDER=%SCHOME%log
rem ログフォルダがなければ作成
if not exist "%SCHOME%log" (
mkdir %LOGFOLDER%
)
set LOGFILE=%LOGFOLDER%\LOG-%DATESTR%.log
echo DATESTR=%DATESTR% >> %LOGFILE%
echo LOGFILE=%LOGFILE% >> %LOGFILE%
echo SCHOME=%SCHOME% >> %LOGFILE%
echo AWS_S3_BUCKET=%AWS_S3_BUCKET% >> %LOGFILE%
echo AWS_S3_BANDWIDTH=%AWS_S3_BANDWIDTH% >> %LOGFILE%
rem コンピュータ名取得
set strHost=%COMPUTERNAME%
set s3path=s3://%AWS_S3_BUCKET%/dailyExport/%COMPUTERNAME%/%DATESTR%
echo s3path=%s3path% >> %LOGFILE%
set BACKUP_FOLDER=%1
echo BACKUP_FOLDER=%1 >> %LOGFILE%
set TARGET_FOLDER=%2
echo TARGET_FOLDER=%2 >> %LOGFILE%
echo. >> %LOGFILE%
rem 引数のチェック
if "%1"=="" (
echo 引数1がありません >> %LOGFILE%
exit 1
)
if "%2"=="" (
echo 引数2がありません >> %LOGFILE%
exit 1
)
rem 引数のフォルダチェック
if not exist %BACKUP_FOLDER% (
echo 引数指定のフォルダがありません >> %LOGFILE%
exit 2
)
rem 処理開始 ====================================================
echo ------------------start %time: =% -------------------------------- >> %LOGFILE%
echo ■バックアップ開始 >> %LOGFILE%
echo □データコピー「%BACKUP_FOLDER%」⇒「%s3path%」 >> %LOGFILE%
rem --同期
rem aws s3 sync %BACKUP_FOLDER% %s3path% --delete >> %LOGFILE% 2>&1
rem --フォルダ再帰削除
aws configure set default.s3.max_bandwidth %AWS_S3_BANDWIDTH%
aws s3 rm %s3path%/%TARGET_FOLDER% --recursive >> %LOGFILE% 2>&1
echo -----------------cleaned %time: =% ------------------------------- >> %LOGFILE%
rem --フォルダ再帰コピー ※ntfsやxfsのファイルシステムと違って空フォルダは維持されない
aws s3 cp %BACKUP_FOLDER% %s3path%/%TARGET_FOLDER% --recursive >> %LOGFILE% 2>&1
if %errorlevel% geq 1 goto ERROREND
echo ------------------finish %time: =% ------------------------------- >> %LOGFILE%
exit /b 0
:ERROREND
echo ------------------finish %time: =% ------------------------------- >> %LOGFILE%
echo ログを確認してください >> %LOGFILE%
exit /b 99
|
バッチのログをローテート#
バッチ処理のログで、保管期間過ぎたものを削除。1週間か10日分ぐらい持ってたらええ。
D:\gvis\rotate.bat - 処理ログの維持
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
@echo off
rem ## -------------------------------------------------------------------------
rem ## Name : rotate.bat
rem ## Created by : gvis
rem ## on : 2023.8.5
rem ## Updated by :
rem ## on :
rem ## Parameters :
rem ## Comments : ログ洗い替え
rem ## Args : なし
rem ##
rem ## -------------------------------------------------------------------------
rem ## ---set env---------------------------------------------------------------
for /f "tokens=1,* delims==" %%a in (D:\gvis\variable.ini) do (
set %%p=%%q
)
echo SCHOME=%SCHOME%
echo LOG_KEEP=%LOG_KEEP%
rem ## ---detail----------------------------------------------------------------
forfiles /p %SCHOME%log /d -%LOG_KEEP% /m "*.log" /c "cmd /c del @file"
rem pause
exit 0
|
ネットワークロードバランサからのs3ログ出力許可#
TLSリスナーがあるとき限定やけど、TLSリクエストに関する情報のみが含まれる場合のみログが出力できるようにできる。
Network Load Balancer のアクセスログを有効にする - エラスティックロードバランシング
IAMポリシーはこんな感じ。
nari-s3-bucket - IAMポリシー
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
{
"Version": "2012-10-17",
"Id": "AWSLogDeliveryWrite",
"Statement": [
{
"Sid": "AWSLogDeliveryAclCheck",
"Effect": "Allow",
"Principal": {
"Service": "delivery.logs.amazonaws.com"
},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::nari-s3-bucket",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "xxxxxxxxxxxx" ⭐️awsアカウントの12桁を指定
},
"ArnLike": {
"aws:SourceArn": "arn:aws:logs:ap-northeast-1:xxxxxxxxxxxx:*" ⭐️リージョンとawsアカウントの12桁を指定
}
}
},
{
"Sid": "AWSLogDeliveryWrite",
"Effect": "Allow",
"Principal": {
"Service": "delivery.logs.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::nari-s3-bucket/*", ⭐️バケット名を指定
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control",
"aws:SourceAccount": "xxxxxxxxxxxx" ⭐️awsアカウントの12桁を指定
},
"ArnLike": {
"aws:SourceArn": "arn:aws:logs:ap-northeast-1:xxxxxxxxxxxx:*" ⭐️リージョンとawsアカウントの12桁を指定
}
}
}
]
}
|
oracleデータポンプ#
oracleにはテーブルとかオブジェクトをバックアップしてくれる仕組みがある。
Oracle Data Pumpの概要
docs.oracle.com
awsのrdsは値段高いけどoracle使わせてくれて、データポンプもできる。
オンプレやec2ホストでoracleにデータやプロシージャとかのオブジェクトを流し込むときは、データポンプ(impdp/expdp)ってコマンドラインを使うけど、rdsではデータポンプのためs3を経由して扱う。
s3経由ダンプをrdsの中に取り出したり、取り込んだりできるっちゅーことやね。
「Amazon S3 統合」 - Amazon Relational Database Service
rds-oracleはあらかじめ作っておく。
sqlplus使うと見づらいから、a5sql使って接続確認までやっとく。

rds-oracleのデータをバックアップするバッチ処理サンプル#
windowsでもlinuxでも、sqlplusは引数にファイルを渡すとその内容を実行してくれる。
linuxのヒアドキュメントっぽいやり方をwindowsでもできるんやろか。
バックスラッシュをlinuxのシェルスクリプトで書くと、次の行を続きとして読み込んでくれるんやけど、この特性を使えばバッチファイルの中にsql書けるかもって思いついた。
windowsでもバックスラッシュいけるんかなぁ。
バッチファイルにsql書いてみたかったのでセコい方法になったけど、やってみたらできた。
rdsでoracle環境は別途作って、実行するec2-windowsホストにはインスタントoracleを入れてsqlplus使える準備しとく。
iniファイル - sqlplus利用#
sqlplusはインスタントoracleをwindowsホストにダウンロードしといて、実行モジュールのフルパスを書いとく。
D:\gvis\variable.ini - 定数定義
1
2
3
4
5
6
7
8
9
10
|
; script base folder
SCHOME=D:\gvis\
; sqlplus fullpath
SQP=D:\gvis\oracleClient\sqlplus.exe ⭐️実行のためのフルパスを設定
; oracle connect
D_ORACON=nariRDS-DB.ue06nsqi2hal.ap-northeast-1.rds.amazonaws.com/nariRDS-DB ⭐️rds-oracleのデータベース
; oracle auth user
D_ORAUSER=admin
; oracle auth pass
D_ORAPASS=xxx
|
バッチ処理本体 - ヒアドキュメント風#
sqlplusにバッチ処理本体のファイルを渡して、バッチ処理内でexitって書いてある行以降にsql書いてる箇所を処理させて動かす。
呼び出すだけなので、sqlでエラーあったかは別で拾う必要がある。別のバッチ処理作らなアカンけど今は省略。
D:\gvis\oraExp.bat - rds-oracleのエクスポート
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
|
rem ^ ⭐️この記述必要 - 次の行をコメント行として判断させるためにこう書く
/* ⭐️この記述必要 - sqlplusに渡したとき、ここからコメントと認識させるため
@echo off
rem ## -------------------------------------------------------------------------
rem ## Name : oraExp.bat
rem ## Created by : gvis
rem ## on : 2024.6.28
rem ## Updated by :
rem ## on :
rem ## Parameters :
rem ## Comments : oracleエクスポート起動
rem ## Args : スキーマ名、日付(yyyymmdd)
rem ##
rem ## -------------------------------------------------------------------------
rem ## ---set env---------------------------------------------------------------
for /f "tokens=1,* delims==" %%a in (E:\gvis\variable.ini) do (
set %%p=%%q
)
rem set DATESTR=%date:~0,4%%date:~5,2%%date:~8,2%
set DATESTR=%2
set LOGFILE=%SCHOME%log\LOG-ORAEXP-%DATESTR%.log
set RC=0
echo SCHOME=%SCHOME%
echo SQP=%SQP%
echo DATESTR=%DATESTR%
echo LOGFILE=%LOGFILE%
echo D_ORACON=%D_ORACON%
echo D_ORAUSER=%D_ORAUSER%
echo D_ORAPASS=%D_ORAPASS%
rem ## ---detail----------------------------------------------------------------
echo ------------------start %time: =% -------------------------------- >> %LOGFILE%
rem ##################################################################################
rem # #
rem # 接続先と定数を指定する #
rem # #
rem ##################################################################################
set CONN=%D_ORAUSER%/%D_ORAPASS%@%D_ORACON%
rem ##################################################################################
rem # #
rem # バックアップ対象のスキーマは引数で指定する #
rem # テスト時は直接指定する #
rem # #
rem ##################################################################################
set BACKUPSCHEMA=%1
rem ##################################################################################
rem # #
rem # 外部ファイルではなくバッチファイルそのものをsqlファイルとして取り込んで実行 #
rem # 「/*」「*/」で囲った範囲と「rem」で始まる行はsqlplus取り込んでも無視される #
rem # #
rem ##################################################################################
echo EXEC_CMD=%SQP% %CONN% @"%~f0" %BACKUPSCHEMA%
echo EXEC_CMD=%SQP% %CONN% @"%~f0" %BACKUPSCHEMA% >> %LOGFILE%
rem pause
%SQP% %CONN% @"%~f0" %BACKUPSCHEMA% >> %LOGFILE% ⭐️sqlplusに接続情報、バッチファイル名本体のフルパス名、スキーマ名渡す
echo ------------------finish %time: =% ------------------------------- >> %LOGFILE%
rem pause
exit
*/ ⭐️この記述必要 - sqlplusに渡してここまでをコメントとして認識させるためで、exitの後ろに書いとけばエラー認識されん
set pagesize 10000
set lin 100
set wrap off
ALTER SESSION SET NLS_DATE_FORMAT = 'YYYYMMDD' ;
spool E:\gvis\log\spool-&_DATE..log
DECLARE
v_hdnl NUMBER;
status VARCHAR2(20);
BEGIN
v_hdnl := DBMS_DATAPUMP.OPEN(
operation => 'EXPORT',
job_mode => 'SCHEMA',
job_name => null
);
DBMS_DATAPUMP.ADD_FILE(
handle => v_hdnl,
filename => '&1..DMP', ⭐️ダンプファイルにスキーマ名つける
directory => 'DATA_PUMP_DIR',
filetype => dbms_datapump.ku$_file_type_dump_file,
reusefile => 1
);
DBMS_DATAPUMP.ADD_FILE(
handle => v_hdnl,
filename => '&1._exp.log', ⭐️ダンプの実行ログにスキーマ名を混ぜる
directory => 'DATA_PUMP_DIR' ,
filetype => dbms_datapump.ku$_file_type_log_file,
reusefile => 1
);
DBMS_DATAPUMP.METADATA_FILTER(v_hdnl,'SCHEMA_EXPR','IN (''&1'')');
DBMS_DATAPUMP.START_JOB(v_hdnl);
DBMS_DATAPUMP.WAIT_FOR_JOB(v_hdnl,status);
END;
/
spool off
EXIT
|
動かすとこんな感じのログが出る。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
------------------start 11:03:24.68 --------------------------------
EXEC_CMD=D:\gvis\oracleClient\sqlplus.exe admin/xxx@nariRDS-DB.ue06nsqi2hal.ap-northeast-1.rds.amazonaws.com/nariRDS-DB @"D:\gvis\oraExp.bat " xxxxxx
SQL*Plus: Release 19.0.0.0.0 - Production on 月 7月 22 11:03:24 2024
Version 19.18.0.0.0
Copyright (c) 1982, 2022, Oracle. All rights reserved.
最終正常ログイン時間: 金 7月 19 2024 10:31:31 +09:00
Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.23.0.0.0
に接続されました。
セッションが変更されました。
旧 13: filename => '&1..DMP',
新 13: filename => 'xxxxxx.DMP',
旧 20: filename => '&1._exp.log',
新 20: filename => 'xxxxxx_exp.log',
旧 25: DBMS_DATAPUMP.METADATA_FILTER(v_hdnl,'SCHEMA_EXPR','IN (''&1'')');
新 25: DBMS_DATAPUMP.METADATA_FILTER(v_hdnl,'SCHEMA_EXPR','IN (''xxxxxx'')');
PL/SQLプロシージャが正常に完了しました。
Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.23.0.0.0との接続が切断されました。
------------------finish 11:03:46.09 -------------------------------
|
データポンプをストアドプロシージャで動かしてるから、結果確認はsql使う。
1
2
3
4
5
6
7
8
|
-- データポンプ結果確認
SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'DATA_PUMP_DIR')) order by mtime desc;
-- ログ確認
SELECT * FROM TABLE
(rdsadmin.rds_file_util.read_text_file(
p_directory => 'DATA_PUMP_DIR',
p_filename => 'xxxxxx_exp.log')) ⭐️スキーマ名指定
where text like '%/rdsdbdata/datapump%xxxxxx.DMP' ⭐️スキーマ名指定
|
例えば、それぞれこんな風に見える。
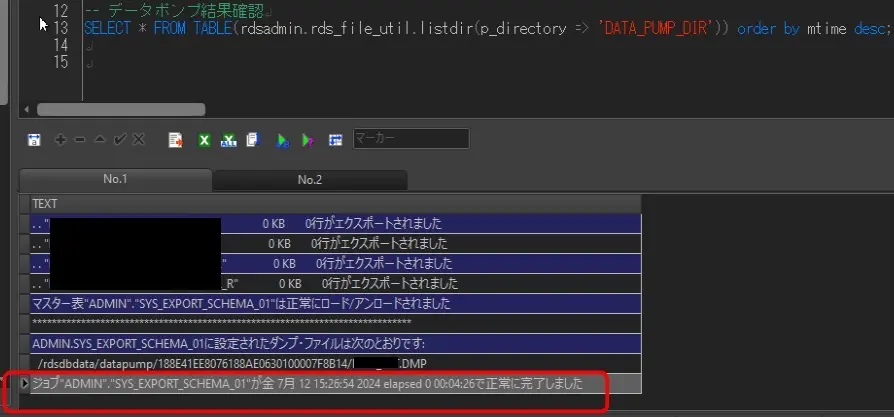
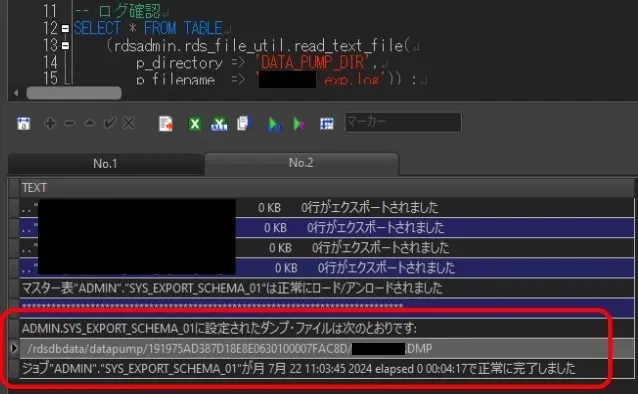
データポンプで出力されたダンプとログはDATA_PUMP_DIRに入ってるから、s3バケットに入れたらええ。
rdsからs3へデータ置く#
s3からrdsへコピーするプロシージャはrdsadmin_s3_tasks.download_from_s3、rdsからs3へはrdsadmin_s3_tasks.upload_to_s3を使う。
1
2
3
4
5
6
|
SELECT rdsadmin.rdsadmin_s3_tasks.upload_to_s3( ⭐️rdsからs3へアップロード指定な
p_bucket_name => 'nari-s3-bucket',
p_prefix => 'めも.txt',
p_s3_prefix => '',
p_directory_name => 'DATA_PUMP_DIR')
AS TASK_ID FROM DUAL;
|

sql実行して得たTASK_IDの値を使って、さらにsql実行すると進捗がわかる。これもちゃんと終わったら、最後にsuccessfullyって出てくる。
1
|
SELECT text FROM table(rdsadmin.rds_file_util.read_text_file('BDUMP','dbtask-1700042165635-1259.log'));
|

ログにsuccessfullyって見えたらs3のwebコンソールに入ったファイルが見えた。
s3からrdsへデータ置く#
s3接続してやりとりをするデータポンプのディレクトリを確認すると、rdsの裏で動くec2のディレクトリが得られる。DIRECTORY_PATHの名前長いな。
1
2
|
select directory_name, directory_path FROM dba_directories
where directory_name='DATA_PUMP_DIR';
|

事前にs3へ何かファイルをアップロードしておく。s3のwebコンソールからローカルPCのファイルをアップロードしとく。

s3にアップロードしたファイルをRDS側へ置くストアドプロシージャを実行する。
呼び出す時の引数を指定して実行すると、TASKIDってのが戻る。
1
2
3
4
5
|
SELECT rdsadmin.rdsadmin_s3_tasks.download_from_s3( ⭐️s3からrdsへダウンロード指定な
p_bucket_name => 'nari-s3-bucket',
p_s3_prefix => 'めも.txt',
p_directory_name => 'DATA_PUMP_DIR' )
AS TASK_ID FROM DUAL;
|

さっきのsqlで得たTASK_IDの値を使って、さらにsql実行すると進捗がわかる。レコードが増えてって最後にsuccessfullyって出てくる。
1
|
SELECT text FROM table(rdsadmin.rds_file_util.read_text_file('BDUMP','dbtask-1700041005377-1259.log'));
|

TASKIDの値でRDSのログを検索すると同じような内容が得られる。何回かsql実行したから、ログの検索対象さっきのとは違うけど・・・。

内容も見える。

URL直接指定でファイルとか扱えるらしい#
他にもいろんな使い方がある。
s3のバケットをweb公開してURL指定で動画とかのコンテンツも見せることができるらしい。
例えば、作業現場で撮影した写真とかをバケットに置いて保管するアプリケーション見たことあるな。
gitにマークダウンで書いたメモをフックさせて、hugoのサイトをs3に置いとくとかやってる人もおられるみたい。
プライベート公開だと、例えば勉強会の座学講座の動画や資料を保管しといて、URLを社内掲示板に公開しといて利用者に見せたりできるんとちゃうか。
単なるファイル保管だけで使うのはもったいないのかもな。
